The Art and Science of Software Estimation - Part 4: Estimating Software
This is a four part article; I’ve divided this article into smaller ~4 min posts to make easier to read and follow up:
- Part 1: Anthropology of Time Estimates
- Part 2: The Nature of Software
- Part 3: Yin & Yang
- Part 4: Estimating Software
Previously in Part 3: Yin & Yang we’ve stared deadlines in the eyes, examined the relation between projects and the passage of time, and we put some scientific labels on various phenomena affecting deadlines and projects.
In this part we get to the juicy meat, the actual activity of estimating software development.
Much of the ideas are recommended by modern agile frameworks such as SCRUM and Xtreme Programming, they have been tested and proven in battle so I suggest that you give them a try as is before modifying them to meet your team or organisation’s needs.
Estimating Software
Two types of problem solving
Software engineering is about solving problems through the means of software, so by software estimation we are predicting the effort we need to put in to solve a set of problems (if they are solvable).
One of the first things we are trained to do as engineers when solving problems is to break them down into smaller workable problems, this aligns well with our human nature of over-inflating our abilities and competence since it forces us to further examine and analyse the problem at hand before we make a prediction or assumption.
In the traditional waterfall model, software problems are usually thoroughly analyse and broken down into very detailed tasks, this allows the implementation team to make a somewhat accurate prediction of the effort needed to implement their solution, however, this method of fully analysing the project has a major pitfall, it fails to account for uncertainty of the future.
As we’ve observed before, software is subject to many unknowns, which means that change (like always) is inevitable. The waterfall model fails to account for such nature, another shortcoming is relevant to the time and cost incurred in the usually long analysis process, that have been rendered useless as a result of the shifting plane.
To account for such nature, the Agile methodology was defined; an incremental and value driven approach to software development in general, the methodology itself is but a mere guideline of how we as engineers and business stakeholders should look at software development as a whole, and as a supplement to those agile principals, frameworks like SCRUM and XP evolved to define a standard operating procedure that significantly improves the life cycle of software development and delivery (DevOps came later to further push delivery to its limits).
Timebox everything
One of the first things you should do is to divide your project into small manageable timeboxes, just like problems, your project’s time and schedule also needs to be broken down.
Dividing the schedule makes it easier to estimate what can be done within those short time periods, start by figuring out your Sprint length; a Sprint is the shortest timebox where your team can build and deliver a fully functioning and working piece of software that an end-user can use, depending on the project, your Sprint could vary from 1 to 4 weeks long, just try to keep it within that length (explaining why that 4 month upper limit exists and/or what happens during the Sprint is beyond the scope of this article).
Next move onto your Releases, a Release can be defined in one of two ways, the first one is to simply take your communicated Deadlines that are probably required by your stakeholders or clients, and simply place a Release on that date (its probably going to be a precise deadline - check Part 3: Yin & Yang for an explanation of the difference between Accuracy and Percission).
If you choose to use this first method, then you’ll have to play a negotiation game on what scope can fit within in Release, so be prepared to convince and use the Agile Golden Triangle a lot.
The second method of defining a Release is to aggregate meaningful problems/solutions together (in SCRUM those are called Epics) and then predict a date where you can expect them to be complete.
Break it down
Which ever method you choose to timebox your project, its important to break down your problems into smaller ones, that way you can better predict the inherent effort required to solve them.
But unlike the Waterfall model, in the Agile methodology we don’t break all problems at once, instead we take an incremental approach and break them down by Releases first; the closer we are to a release the more details we have about the problems we are solving in that release:
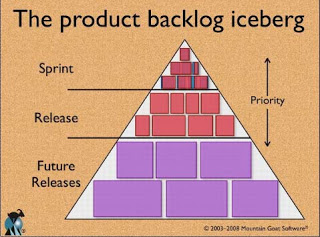
This incremental approach to breaking down your requirements leaves room for the creep of uncertainty in the future, and balances out the time and cost investment into the analysis of the requirements.
While most Agile frameworks recommend that further detailing be done in each Sprint, I recommend that you spend the most time detailing while planning your Release, and only further detailing during a Sprint planning session when needed and required.
Complexity
Now that you have your requirements and problems in a small and workable form, its time to estimate, now you get to be the oracle and predict when those requirements can be fulfilled.
But before you play psychic, DON’T ESTIMATE IN TIME, remember in Part 1: Anthropology of Time Estimates we observed how we define units and measurements, so its important that we stick to the same approach when we are estimating effort required for an unknown.
Instead of time, use a relative unit of measurement, so instead of saying “This task will take me 10 hours”, you should say “This task is 2 times harder than that task that took 5 hours”, in doing so, you are estimating Complexity, a much more valuable measure of a problem than the time it takes to solve it.
The exact way to estimates of complexity is beyond the scope of this series, however I recommend you Google Poker Planning and/or watch Mike Cohen’s videos on the subject on Youtube for a nice intro on the subject.
Capacity and Velocity
Once you have your time boxes, and estimates, you can now start measuring capacity and velocity.
Capacity is the amount of complexity your team is able to deliver, while Velocity is the speed at which your team delivers such complexity.
Both measures go in tandem, with Capacity you define how much complexity you can take in a timebox, whether that be a Sprint or Release, and that definition is always based on your team’s most recent Velocity measure in the previous timebox.
Those two measures will continually vary, sometimes they increase, other times they decrease, and plotting those variances on two dimensional graph will give you a nice dataset to conduct regression analysis and define your Undeadline.
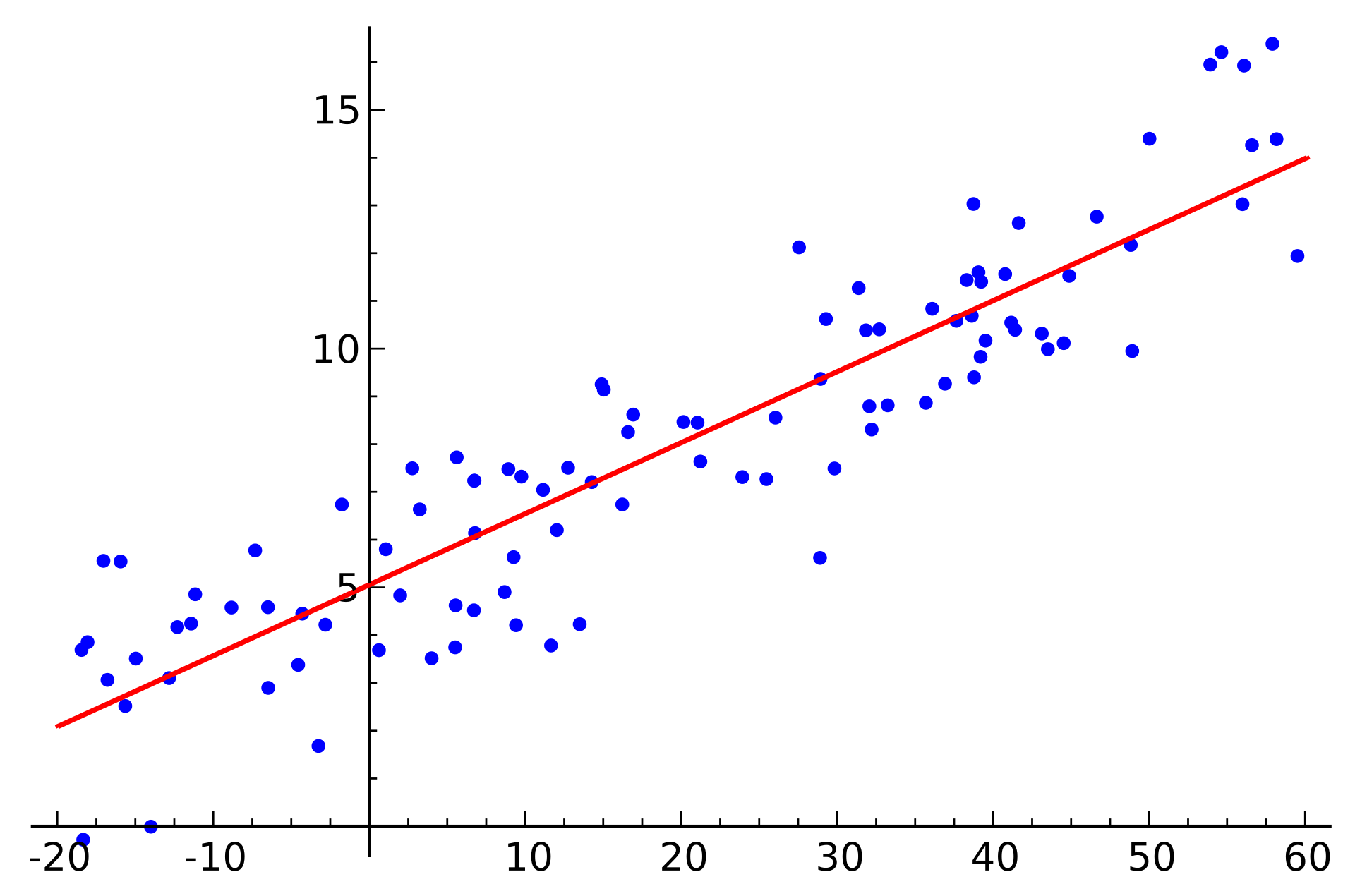
Tying everything up
By now you should’ve learned the limitations we humans inhibit when it comes to predicting the future success/failure of our efforts, the uncertain and ever changing nature of Software in general, the different variables in play when it comes to deadlines and projects, and how you can decrease the variance of your estimates by timeboxing your project’s schedule, estimating in complexity and revising your capacity.
This series is just scratching the surface of the subject which is a vast field of study that many are consistently trying to improve, so I encourage that you read more on the subject.
My reading recommendations are:
- SCRUM: The Art of Doing Twice the Work in Half the Time
- Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations
- The Goal: A Process of Ongoing Improvement
- The Pheonix Project
- Lean Software Development: An Agile Toolkit
Finally I’d like to encourage your feedback and questions in the comments section below, I’m sure that your feedback will definitely help me and that your questions will definitely help others having the same questions.
-
Original image by Sewaqu Regression Analysis ↩︎